TRecs: Declutter Recommendations by going Real-time
As a performance-oriented growth platform, AdRoll is always looking for ways to improve our users’ ad experience. Our Dynamic ads are the highest performing ad type, but some of the underlying systems were becoming increasingly hard to scale and change. In this post, we will talk about how moving those systems to a real-time service made our product more nimble, scalable and easy to A/B test.
15-20 minute read
High Level Problem
Our Dynamic Ads product is designed to show a user ads with specific, recommended products based on their browsing history. Each advertiser gives us a list of all of its products beforehand so that we can generate a “product catalog” for the advertiser. Using this product catalog and AdRoll’s raw logs, we use algorithms to generate both per product and per advertiser recommendations daily via Amazon’s EMR service. Each ad is not associated to a single algorithm but to a combination of algorithms and weights called the product stream.
So, in order to serve relevant recommendations to our users based on their browsing history, we had an offline processing job that precomputed recommendations for each permutation of every product stream, for all the products in our every advertiser’s product catalog daily (and advertisers can have millions of products). These pre-generated recommendations were stored in a dynamodb table and served via an akamai fronted endpoint.
While this process worked for awhile, we ran into both scaling and ad performance issues:
- Only 1% of the 600 million (3TB of data) precomputed recommendations stored in DynamoDB table were being used on a daily basis.
- The Javascript that loads at ad render time was responsible for getting recommendations from the DynamoDB table for every product that the user had interacted with. Because of the strict response time constraints, if the recommendations didn’t return in time and there weren’t enough products to animate the ad, a failsafe (static) ad was shown. Obviously, our customers who expect to see dynamic ads were not pleased that a percentage of their traffic was seeing static ads.
- Our product recommendation A/B testing framework tests variations at a product stream level. Every time a product stream was created, new recommendations were generated for every product in our system for that product stream. Thus, every new experiment almost duplicated the entire data set, doubling Dynamodb writes everyday, thereby increasing costs and also deteriorating the table’s performance.
Given these challenges, we determined that a real-time system that would generate only the needed recommendations for each displayed ad made the most sense. We had to build a multi-region, light weight, highly available, easily scalable service with fast response time (under 50ms) and a robust fallback mechanism.
In order to accomplish this task, we needed to do the following:
- Centralize all the recommendation metadata.
- Replicate underlying data to all the regions to support a multi-region service.
- Translate the offline processing job into a real-time API.
- Deploy the new service in multiple regions.
- Implement an effective load balancing solution.
- Come up with a rollout plan to smoothly switch the production traffic to the new system and shutdown the old system.
Design
This diagram shows real-time recommendation system in one aws region.

Data Sources
Our real-time recommendation service a.k.a TRecs has a stateless retrieval API that fetches information from the underlying data sources in real-time to generate recommendations. In this section, we will go over the the data sources needed for building recommendations and the modifications we did to each of them to make this data easily consumable by trecs.
-
Recommendation metadata
We have several EMR jobs in our system which are responsible for generating product recommendations for each of our recommendation algorithms. For legacy reasons, these EMR jobs wrote data to varied data sources like postgres, hbase. In order for the real-time API to work, we needed to aggregate all the algorithm data with a standardized scoring method in a low latency data store.
We were looking for a fast, scalable, consistent and cost effective data store. Elastic cache and Dynamodb were our top contenders. Given the recommendation metadata is generated by batch jobs, the writes were expected to be non-uniform. Since dynamodb costs depends on throughput rather than storage, using dynamodb with autoscaling was a more cost effective option than elastic cache. Thus we chose dynamodb as our data store.
We updated each EMR job to write the data to a new DynamoDB table where the key would be advertiser_id/algorithm/source_product_id and the value would be the recommended products, represented as a comma separated string of product_id’s with the first product listed being the most relevant recommendation. We leveraged the dynamodb’s BatchWrite interface to make the writes as fast and efficient as possible. -
Product metadata
Our product data pipeline already parsed our advertiser’s product catalogs and stored the product metadata in a Dynamodb table. Since the nature of writes for this datasource was also non-uniform, fetching data from dynamodb (with autoscaling enabled) was a high performant and cost effective option for TRecs. So, we didn’t have to tweak this data source. -
Cookie Interactions data
Our Ad servers record cookie interactions in every aws region in a Dynamodb table. Thus, this data was readily available for use. -
Advertiser metadata
TRecs needs advertiser meta information in real-time to filter out stale & blacklisted products. This data is present in RDS(postgres) and as you can imagine, it doesn’t update as frequently. So, we created a task that runs every quarter of an hour and dumps the relevant data from postgres onto a file in S3. This file is then loaded into the TRecs server memory once every 15 mins. In order to fetch this file with minimum latency from all TRecs regions, we configured Akamai to front the S3 bucket.
Data Replication
Before TRecs service came into existence, most of our dynamic ad infrastructure (pipelines and data sources) was geo-located only in us-west AWS region and relied on Akamai’s CDN to serve product recommendations to our ads globally. In order to achieve fast response time with multi-region real-time recommendations service, the underlying data had to be available in all the aws regions where TRecs service was going to be hosted. Thus, we had to replicate recommendation metadata and product metadata to three other aws regions. Since Dynamodb was the underlying data store, we had to solve Dynamodb cross region replication problem.
Replicating Dynamodb data is a two part process:
-
One time table copy
We leveraged AWS Data Pipeline’s DynamoDB Cross-Region Copy feature for doing the one time table copy. It uses s3 as the intermittent storage to copy the data. Launching the EMR job in the same region as the destination table and increasing the (read/write) provisioned capacities on both source and destination tables enabled us to complete the one time table copy process faster. -
Setting up real-time updates
Setting up real-time updates was non-trivial. Common idea was to apply live DynamoDB stream records from the source table to the destination table to get real-time updates. We had two options to leverage Dynamodb streams, either use an in-house developed solution or use AWSLabs Dynamodb cross region library. The in-house solution needed a few tweaks to be usable but the aws solution almost worked out of the box for us, so we decided to go with that. While this system worked well with small test traffic, we saw a lot of write throttles on the destination tables when we rolled AWSLabs Dynamodb cross region library to production. Thereby ironically failing to replicate real-time updates. It turns out that Dynamodb streams don’t copy data at a uniform rate. Since both product metadata and recommendation metatadata source tables have bursty traffic and rely on autoscaling, the destination tables weren’t able to scale at the same rate as the source table causing records to be dropped. Alas, we had to scratch the AWSLabs Dynamodb cross region library solution and modified our product pipelines/EMR jobs instead to write to Dynamodb tables in all the regions. Since our offline systems only exist in us-west region, we had to scale them up to absorb additional network latencies that were incurred while writing to Dynamodb tables in three other AWS regions. AWS recently announced global tables to solve for Dynamodb data replication problem. We are waiting for global tables to be available in the Asia Pacific regions to try it.
Real-time recommendation service (TRecs)
Our Real-time Recommendation service is built using Dropwizard, a Java framework for RESTful web services. It runs within a docker container deployed on a standalone AWS ECS cluster. We use terraform templates to launch the underlying AWS infrastructure. It is deployed using jenkins2. We use datadog for montoring and logentries to collect logs. TRecs is integrated with JMX to collect jvm and jetty stats for monitoring and optimizing our environments.
The TRecs API
It’s a HTTP GET API which is called for all dynamic ads from Javascript at ad render time to fetch recommendations for a given user (cookie). The API does the following in real-time to generate recommendations:
- Fetches cookie data
The API gets a list of cookie interacted products from the cookie metadata table. - Fetches recommendation metadata
As mentioned earlier, every dynamic ad is associated with a product stream. Each product stream has multiple recommendation sources associated with it and each recommendation source has a weight. The weight is used to determine how we should weigh various sources with respect to each other. Both per-product recommendations and per-advertiser recommendations are fetched from recommendation metadata and a confidence (or score) is assigned to each recommendation. - Processes recommendation metadata
It’s very likely that the same product gets recommended by multiple sources, thus we need to “blend” those recommendations to come up with a normalized recommendation. Recommendations are then sorted on confidences and deduped. - Fetches product metadata
For each of the recommended products, product metadata is fetched from the Dynamodb table. - Filters products
We run a final check to filter out stale and blacklisted products before returning the list of recommendations to the dynamic ad.
To reduce network latency, the API leverages Dynamodb’s BatchGetItem on every step of the way. Since each Dynamodb item is only a few bytes, a single batch call can fetch up to 100 items. This vastly improved our API’s response time.
Load balancer
TRecs API is fronted by an endpoint in the adserver. Since cookie values are only accessible from the same domain as they are set on, to get the adroll cookie, we had to route the dynamic ad traffic to TRecs via the adserver.
To scale the service horizontally, we were looking for a fast,reliable and cost effective load balancer for TRecs. It was mostly between choosing AWS ALB service or an in-house developed load balancing erl library. While AWS ALB worked well, we realized that AWS not only charges for keeping the ALB running but also charges for per unit traffic served by it. Since the recommendation service will experience high throughput, AWS ALB would have been a very pricy option.
Given, we were already forwarding the traffic to TRecs via the Erlang web server, it was fairly easy to integrate the in-house load balancing library in the same endpoint.
Fallback mechanism
Coming from a system where all the recommendations were precomputed, Dynamic ads never experienced missing recommendations due to system outages. To ensure the dynamic ad performance remains unaffected during request failures / system outages, It was very important to have a robust fallback mechanism with reasonable response times. We deployed a “slim” version of the precomputed recommendations offline job to generate only per advertiser recommendations and store them in S3. We use a Akamai fronted s3 endpoint to fetch these recommendations to save us from replicating them across AWS regions while allowing faster response times.
Rollout plan
We did the following to ensure a smooth switch to the new recommendation system -
- Performed multiple load tests to make sure the TRecs service lives up to the throughput and response time SLA’s.
- Turned on data replication to replicate underlying data sources to three other AWS regions
- Deployed tasks to dump the needed data in S3
- To rollout the traffic to our new recommendation system incrementally, we leveraged our recommendation A/B testing framework.
- While scaling up the traffic to TRecs, we used presto to query our raw logs to validate the ad recommendation performance.
- Refactored the javasccript code that runs at ad render time to use TRecs as the primary recommendation service
- Migrated other systems at adroll to use TRecs
- Sunset the old recommendation system
Performance
We are very excited to share the improvements of our Real-time system
Fast response time
TRecs API has a median response time of ~30ms and can support over 1 million requests per host per hour 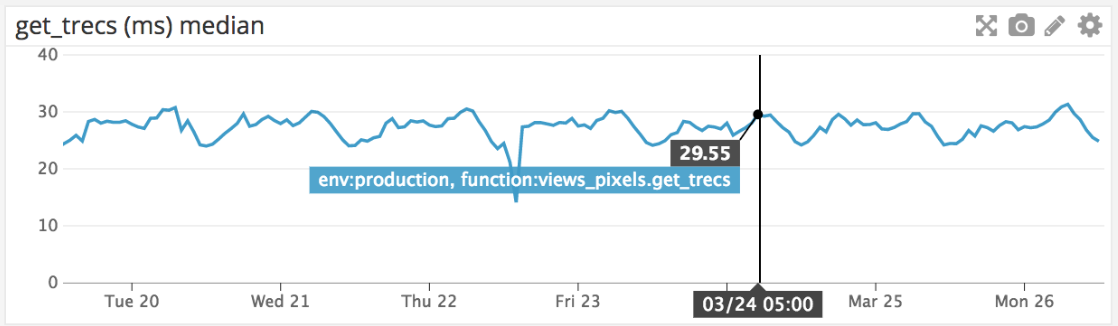
Easy to scale
It is deployed as a ECS service which is easy to scale horizontally
Better product recommendations
The recommendations shown in a dynamic ad is a combination of user interacted product recommendations and top products for that advertiser. Since TRecs filters stale products in real-time, our dynamic ads saw a 10% increase in user interacted recommendations. Showing more relevant recommendations leads to better ad performance.
No additional costs to A/B test new recommendation algorithms
We don’t have to precompute recommendations to test new algorithms. This has unlocked the opportunity to test and rollout new algorithms which will help improve dynamic ad recommendations
Fewer network calls to fetch recommendations
The dynamic Ad has to make one network call to fetch all the recommendations, making the ads respond faster
Easy to troubleshoot
Previously the recommendation functionality was split between the offline recommendation job and the Javascript ad render component, making it difficult to troubleshoot recommendations served for a given advertiser, cookie combination. But with TRecs, debugging such issues has become a lot easier as all the functionality is wrapped in a single API.
It has been fun working on this project. We hope this post is helpful for people who are looking to transform their offline systems to real-time services using AWS services. This project is a good illustration of the type of work we do on the Dynamic Ads team. If this piques your interest Roll with Us